As I wrote in
my last post, today I'll be quite technical with the
margin of error of my computation. And some considerations to try to mimimize this error in the end of my post. Last time on
Veronising: I chose
a hierarchy of terms which have higher and higher Google Trends curves, to evaluate, by a sequence of rules of three, the frequence of Google searches for the highest term compared to the least looked for.
For the computation I intuitively chose the words such that for each pair of consecutive ones, the first one had a peak approximately twice as high as the second one. The margin of error when reading the value of the curves is approximately 1 pixel, but this absolute error is not the same relative error on the higher, and the lower curve. The higher one always peaks at 113 pixels: 1 pixel of error is less than 1% here. However if the lower one peaks at 50 pixels, it will be a 2% error. If the curve is never over 3 pixels, then the error is more than 30%! So do we have to choose a hierarchy of curves very close to each other? Not necessarily, because in this case we may
indeed reduce the error at each step of the computation, but we increase the number of steps (thus, the number of errors) between the least and the most seached.
I couldn't help but mathematically modeling this delicate balance that I've just expressed in a sentence. I call
a the ration between the max of the highest and the lower curbe within a pair of consecutive ones (thus
a>1). To simplify the problem, I consider that this ratio is
constant in my whole scale of words. Then, ideally, I would like to find a word 1 searched
x times a day on Google, a word 2 searched
ax times, a word 3 searched
a2x times... a word
n+1 searched
anx times.
Now, let's compute the error: instead of reading a height of
k pixels for a word, and
ak=113 for the next one, say I make an error of 1 pixel, each time too high
(this is a pessimistic assumption, actually the error probably alternates, once one reads too high, once too low...). In my computation, without error with the rule of 3 I should find as the number of searches for the highest term:
x.113/k = x.ak/k = xa
The problem is my 1 pixel error, so when I apply the rule of 3 I get in fact:
x.113/(k+1) = x.113/(113/a+1) = x.113a/(113+a)
Thus at each step I multiply by 113
a/(113+
a) instead of multiplying by
a, so for the most searched word, I find
x(113
a/(113+
a))
n instead of
xan. I underestimate the real value, so to minimize the error I must find the
a>1 that maximizes
x(113
a/(113+
a))
n.
Second part of the computation: the number of steps, that is
n+1 words, of course... but this
n depends on
a. Indeed we consider that the least searched word (
x times) and the most searched one (
x'=
xan times) are fixed. Then
x'=
xen ln a, so ln(
x'/
x)=
n ln
a and finally
n=ln(
x'/
x)/ln
a.
We put this into the upper formula, so we underestimated all the words of the hierarchy, and the highest was evaluated to:
x(113a/(113+a))ln(x'/x)/ln a
which we now have to maximize according to a. A quick analysis of this function at its limits shows that it tends to 0 in 1
+, and to 1 in +∞. Very well, it expresses the dilemma I was mentioning in the 2nd paragraph. However it doesn't give us where the max is reached, and neither
Ahmed the Pysicist, nor
Julian the Mathématician, helped respectively with Mathematica and Maple, could give me a nice formula, there are still some ugly
RootOf(...) in the formula.
No problem, we'll just find an
approximation using Open Office Spreadsheet. The file is
there, and here is the curve obtained for a ration of 20,000 between the most searched and the least searched word
(the figure approximately corresponds to what I found for my hierarchy):

So the minimal error is reached for
a approximately equal to 2.75 (i.e. a maximal height of 41 pixels for the lower curve). Then it's less than 25%. Of course it seems a lot, but remember the remark on how pessimistic this scenario was, with errors cumulating by successive underestimations. I still have this interesting theoretical question:
is it possible to compute the expectancy of the error on the computed value of the most searched word, if at each step the error randomly varies between -1 and +1 pixel? ?
One can also notice the curve increases a bit faster on the left than on the right. As shown in green on the graph, it seems that
we'd better choose a hierarchy such that consecutive reference words have a number of searches ratio of 4 rather than a ration of 2.
Now, here are some other hints to improve the accuracy of the computation. First, measure accuracy: instead of just measuring the maximum, where we know there is an inevitable error, we can try to compute it from measures with less errors. I come back to my example from
the previous post with cat, dog, and phone:
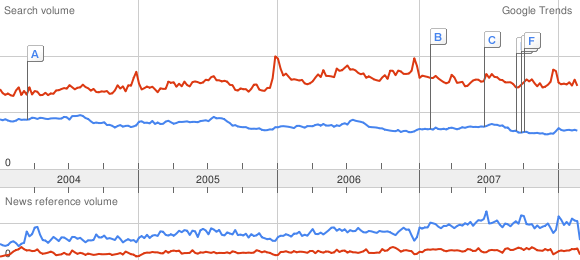
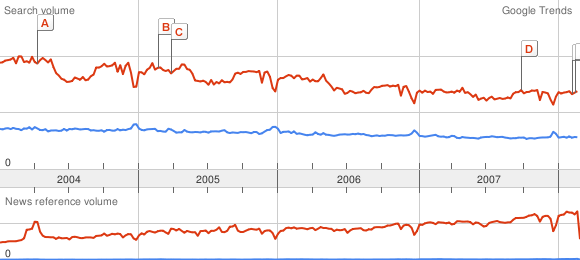
Comparison cat ~ dog (curve 1) : 65 px
~ 113 px
Comparison dog ~ phone (curve 2) : 69 px
~ 113 px
Except that instead of measuring the maximum of dog, we can evaluate it the following way: do the average of the values of the curve 1 for dog, the average of the values of the curve 2 for dog. Then deduce a very accurate scale change. Finally multiply the maximum of dog on the curve 1 (that is exactly 113 pixels, no error here) by this scale change!
Another problem now: how to obtain the average of the values of a Google Trends curve? With the
CaptuCourbe, of course! Be careful here: some values may not be retrieved by the CaptuCourbe
(color problem, for example the curve is cut by a vertical black line hanging from a Google News label bubble). So you have to compute the average of the curves on values you really managed to retrieve!
One more thing, the CaptuCourbe
is not very accurate because it
gets the values of all pixels of some color from a curve, and computes the average, for each column of retrieved values. I've developed a new version, online soon, which allows to get the
maximum of the heights of pixels of some color. I'm using this functionality in my method to compute the max, however it's still the average choice I make to get the average of the curves. This is not a small detail, as you can see on the
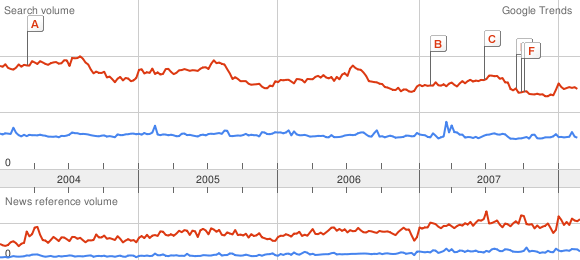
Britney Spears Google Trends curve, that I extracted in both ways:

A 20% error in the measure of many peaks using the pixels of the same color is really something!
So, to close this series of posts on the vertical scale of Google Trends, I still have some questions left. First, get a "value of the foo" in the number of daily searches. Then I could try to program the whole chain of curve retrieval, measures, and computations, as described in my first post, to provide a utility which would add the vertical scale to a Google Trends curve. Anyway don't expect too much, I'd better wait and see whether the API Google is preparing will provide this data.
Estimating the number of searches for some keyword is still a nice challenge., I've discovered
GTrends Made Easy, a freeware which gives some estimations computed with a method similar to mine here
(in fact he does only 1 rule of three, comparing the request word with a reference word for which he knows the number of Google searches, approx 500 ; that is words which appear between 5 and 50000 times a day, that is less than 100 foo), which was described on this
YouTube video.
This post was originally published in French: Rétroingéniérie de Google Trends (2) : marge d'erreur.
 xkcd is really great to illustrate your lectures (or to spend some time on weekends), when you teach computer science. But not all French students understand English well enough. Well, sometimes I don't understand some subtle lines myself...
xkcd is really great to illustrate your lectures (or to spend some time on weekends), when you teach computer science. But not all French students understand English well enough. Well, sometimes I don't understand some subtle lines myself...





 Even if I'm not an expert in
Even if I'm not an expert in  Recipes are so accurate: you get a list of ingredients with exact quantities, and how to use them, but no warranty on what happens if you don't exactly respect the quantities. That's why I will define a tool to represent
Recipes are so accurate: you get a list of ingredients with exact quantities, and how to use them, but no warranty on what happens if you don't exactly respect the quantities. That's why I will define a tool to represent  From the lower left to the upper right, the number of eggs in the recipes decreases (as there is more and more flour and milk). On the upper left corner we have lots of flour, and on the lower right corner, more milk. And what is this kind of
From the lower left to the upper right, the number of eggs in the recipes decreases (as there is more and more flour and milk). On the upper left corner we have lots of flour, and on the lower right corner, more milk. And what is this kind of 
 Well, just wait before pouring your "pâte à crêpes" onto waffle iron: you may want to add some
Well, just wait before pouring your "pâte à crêpes" onto waffle iron: you may want to add some Here again what wa see is a convex hull, in 3 dimensions, on dots (x,y,z) where x is the number of eggs, y the quantity of milk and z the quantity of flour. I put the dots by choosing a minimum limit and a maximum one on the number of eggs to get this
Here again what wa see is a convex hull, in 3 dimensions, on dots (x,y,z) where x is the number of eggs, y the quantity of milk and z the quantity of flour. I put the dots by choosing a minimum limit and a maximum one on the number of eggs to get this 

 Anyway, following the first hours gave me the opportunity to see how fast the web reacted. As I mentioned it, the
Anyway, following the first hours gave me the opportunity to see how fast the web reacted. As I mentioned it, the 









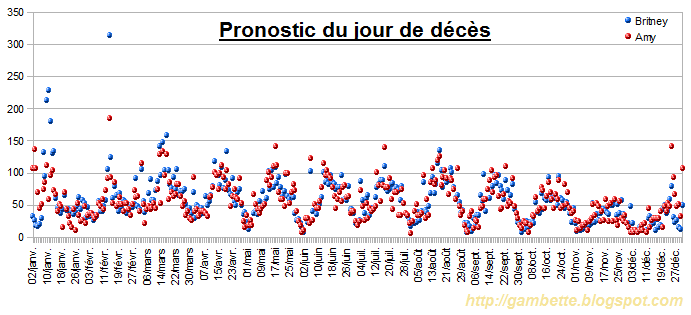







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}